
We adopt autonomous driving as our primary testbed to demonstrate test-time scaling—an ideal yet challenging domain with high demands for realism, diversity, and efficiency, aligning with COSMOS’s target use case.
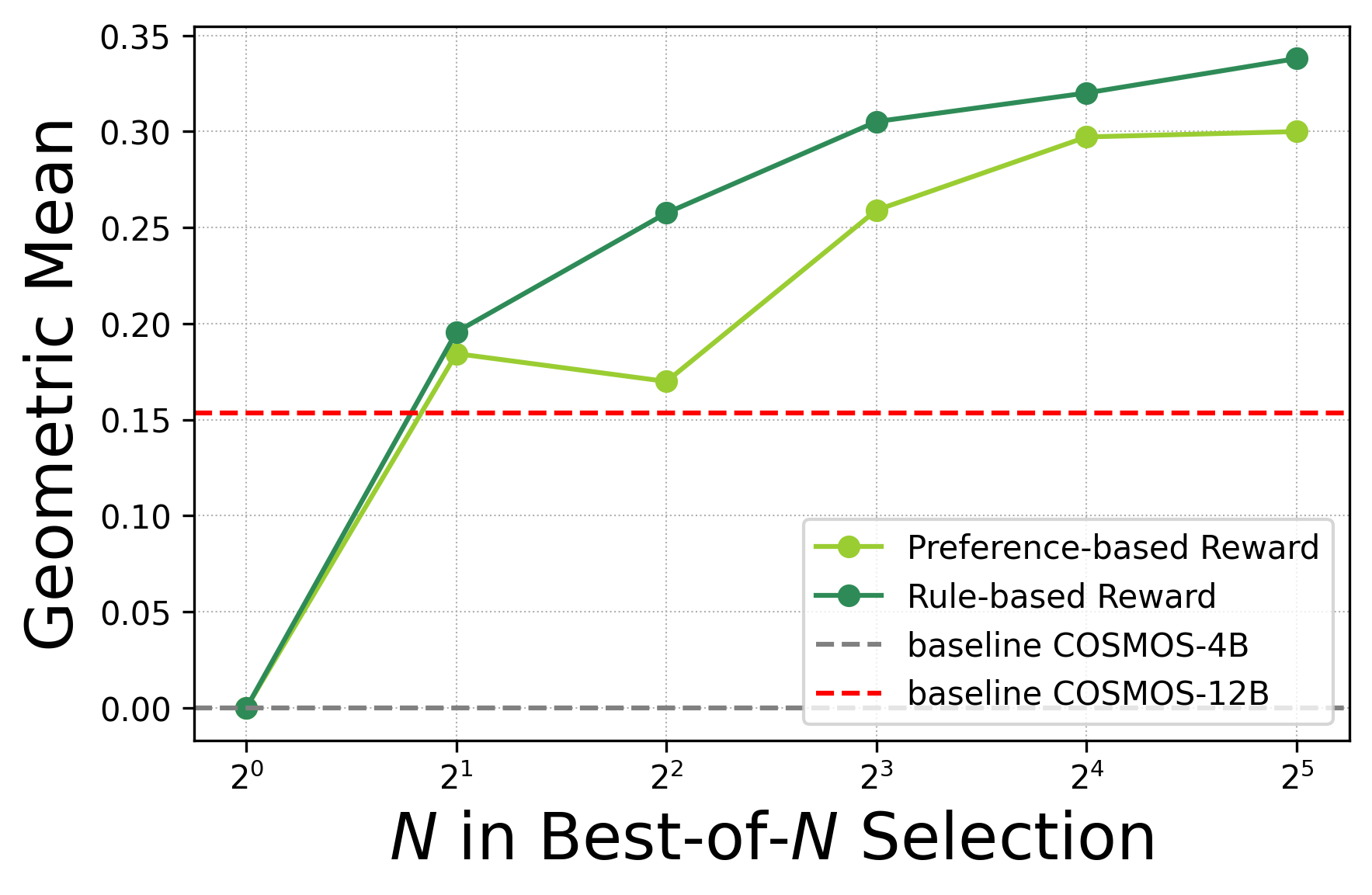
We Use Rule-Based Rewards for Robustness and Extensibility since they consistently outperform preference-based ones.
Test-Time Scaling Exists in WFM—even with a naive best-of-N. Simply sampling more candidates improves quality.
Test-Time Scaling Is Surprisingly Compute-Optimal: a 4B model with test-time scaling can match or exceed a 12B model under the same FLOPs.
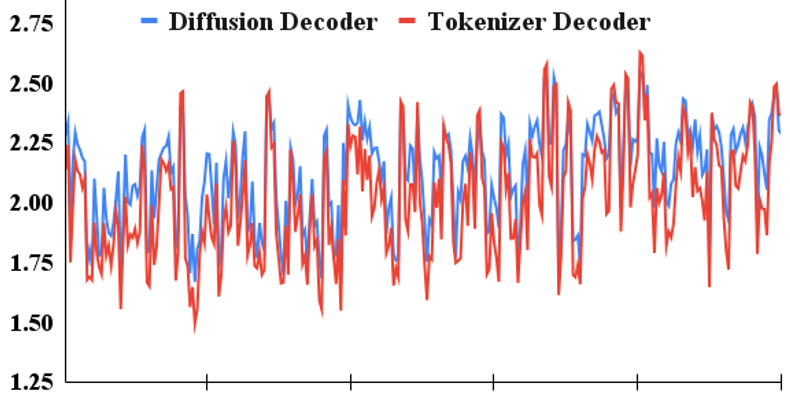
Due to costly decoding with diffusion models, SWIFT uses a fast tokenizer decoder to accelerate decision process.
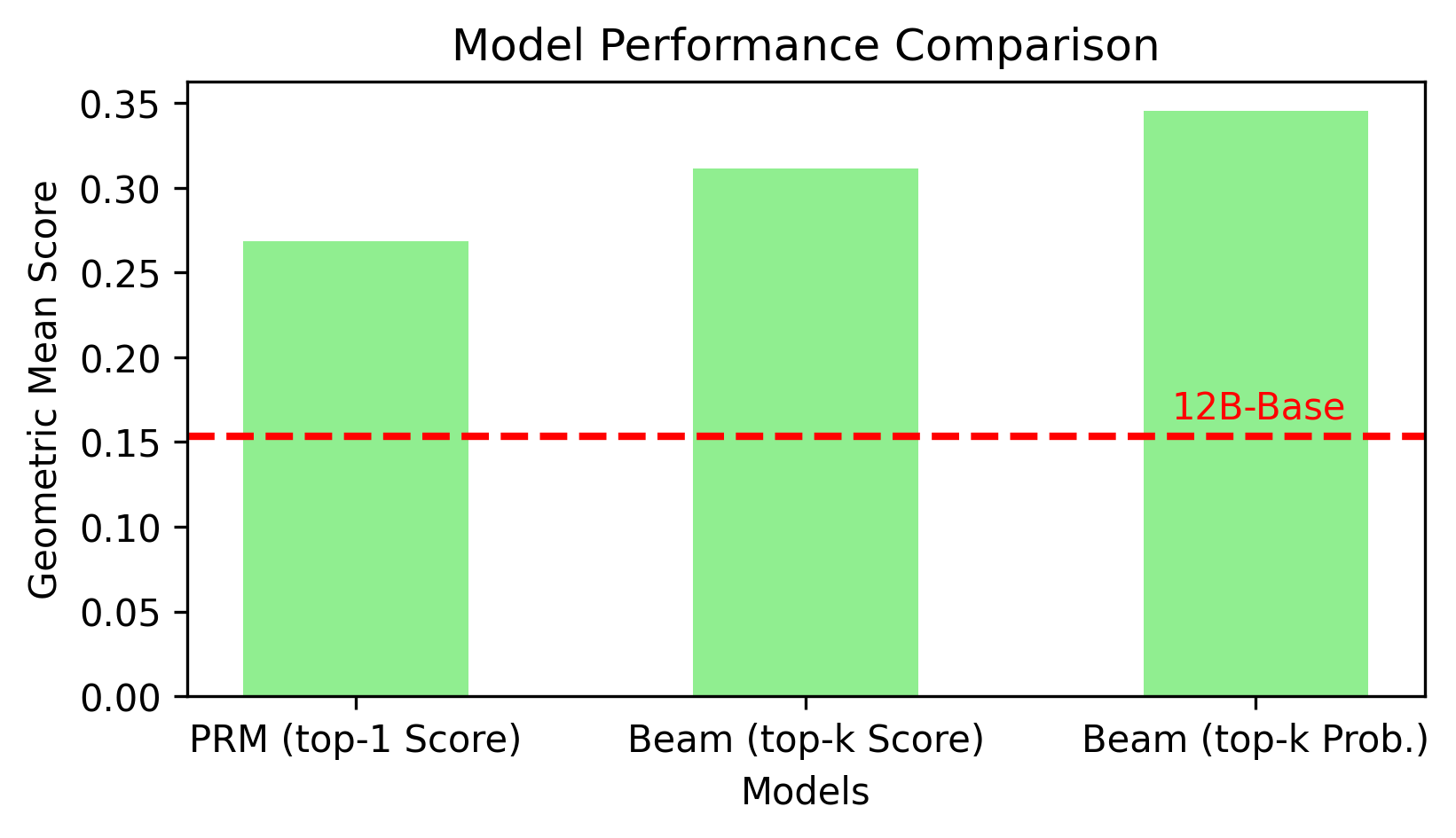
Probability-based top-K pruning introduces controlled exploration, better than both top - 1 sampling and deterministic top-K sorting
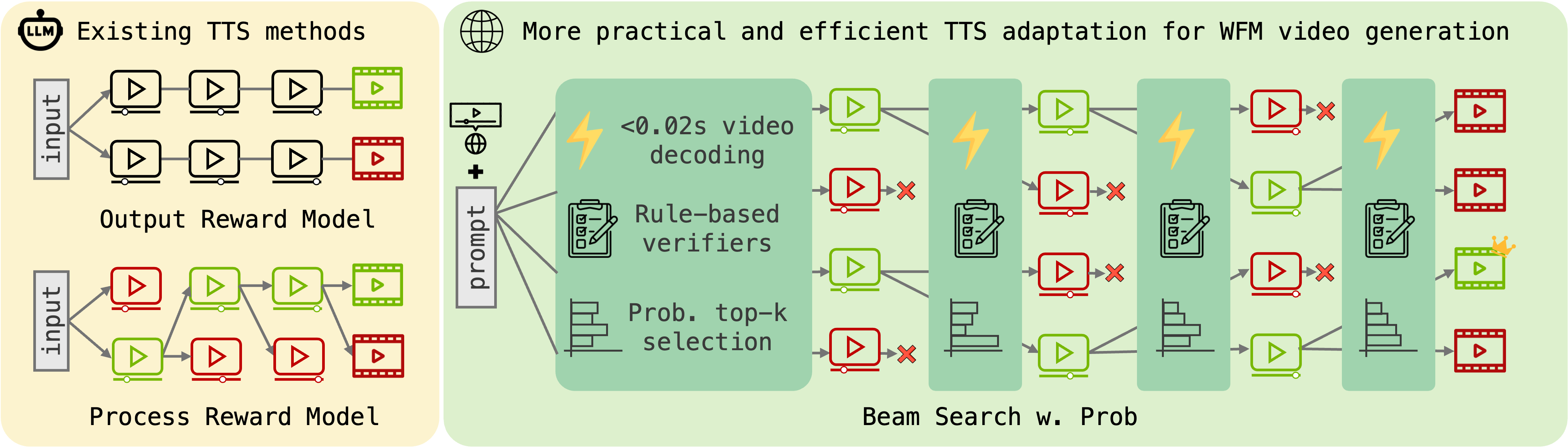
Adapt Test-Time Scaling Strategy to WFMs Practically and Efficiently by using fast decoding, probability-based top-K pruning, and beam search.
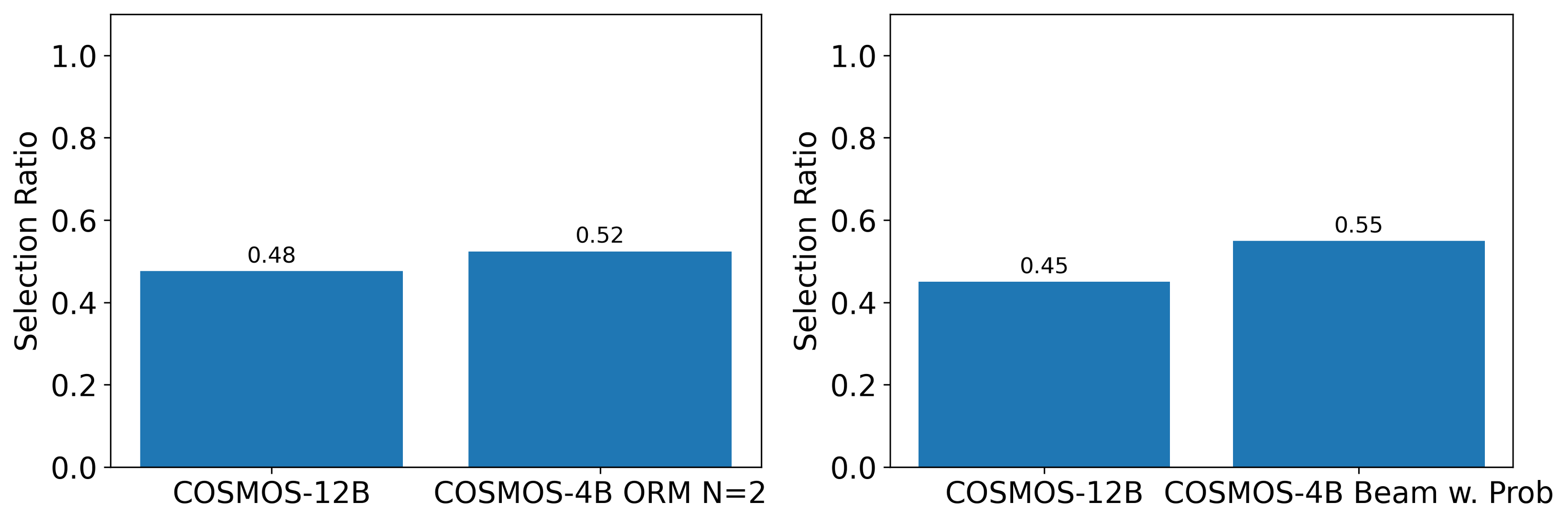
Human Study: outputs from the smaller model enhanced with test-time scaling are often preferred by human over those from the larger baseline.